Deep Learning in Kotlin: hoe jij met KotlinDL aan de slag kunt!
Door Marcel van Heerdt / apr 2022 / 1 Min

Door Marcel van Heerdt / / 7 min

Veel teams kiezen een programmeertaal die past bij het project waar ze aan werken. De argumenten voor het kiezen van een programmeertaal kunnen ver uiteenlopen, van leesbaarheid tot performance en security. Bij specifieke projecten kunnen bepaalde libraries nodig zijn, die niet beschikbaar zijn voor alle programmeertalen. Dit is ook het geval bij het gebruik van AI-libraries. Deze libraries zijn vaak alleen beschikbaar voor Python, waardoor het gebruik van Python een vereiste wordt, of zij zijn wel beschikbaar voor andere talen, maar worden niet officiëel ondersteund.
Naast de beschikbare libraries wordt Python gezien als een prettige taal voor AI-experimenten, vanwege de flexibiliteit en eenvoudige leercurve. Voor het ontwikkelen van een productiewaardig systeem zijn deze argumenten minder relevant, waardoor in volwassen projecten Python minder vaak gebruikt wordt. Bij een volwassen systeem worden andere argumenten, zoals stabiliteit en onderhoudbaarheid, juist belangrijker.
Met deze verschillen moet omgegaan kunnen worden in een project die zowel productiewaardig moet zijn als gebruik moet maken van AI. Hiervoor stellen wij het opsplitsen van de applicatie voor. Een deel van de applicatie, geschreven in Python, is verantwoordelijk voor AI en voert alleen die taak uit. Andere delen, geschreven in één of meerdere andere programmeertalen (bijvoorbeeld Kotlin), zijn verantwoordelijk voor alle andere logica. Hiervoor kan bijvoorbeeld een microservice architectuur gebruikt worden, waardoor je voor iedere service de programmeertaal die past bij de verantwoordelijkheden kunt kiezen. De delen van de applicatie communiceren met behulp van RabbitMQ.
Aan de hand van een casus en codevoorbeelden neem ik je mee door de implementatie van een applicatie die uit meerdere services bestaat, die onderling communiceren met behulp van RabbitMQ. De codevoorbeelden zijn terug te vinden in het project op GitHub, waarvoor de link en uitleg onderaan de blog te vinden zijn. Zo kun je zelf meedoen bij het implementeren van een applicatie, door onze casus of een andere casus naar keuze uit te werken!
De casus die ik je in deze blog laat zien gaat over een brouwerij die meerdere soorten bier kan brouwen. De gebruiker moet een foto van een biertje aan kunnen bieden, waarna de brouwerij het bier op de foto gaat brouwen.
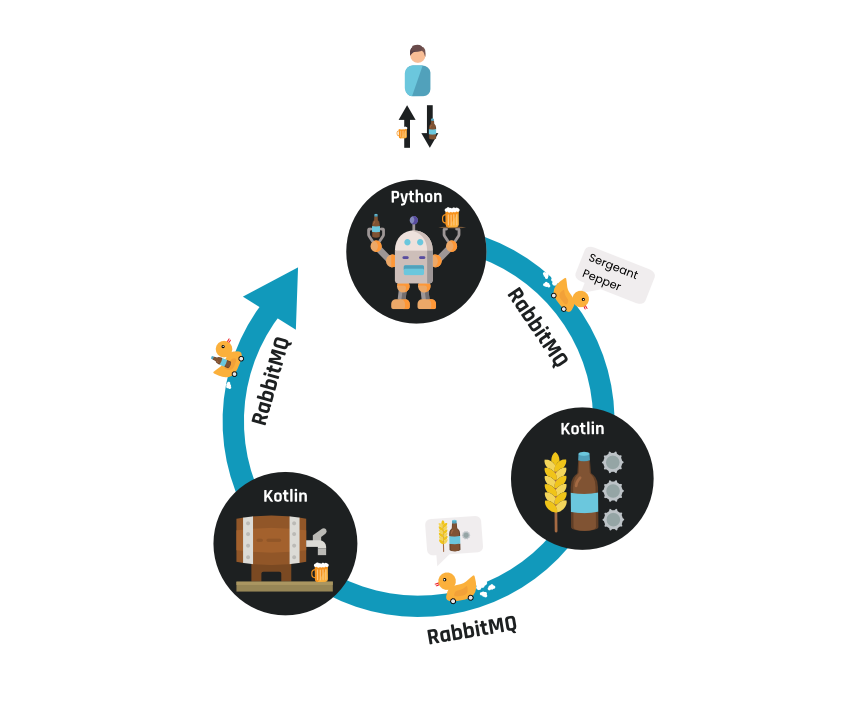
Het brouwproces bestaat uit een aantal stappen:
Tussen deze stappen moeten berichten gestuurd worden om de volgende stap te activeren. Berichten moeten dus van Python naar Kotlin en andersom. Hiervoor wordt RabbitMQ ingezet. In onderstaand diagram is te zien hoe de gebruiker alleen interactie heeft met de beer machine, waarna het proces langs de andere services loopt.
RabbitMQ is een open source message broker die we als voorbeeld gebruiken in deze blog, je zou ook elke andere message broker kunnen gebruiken. Door de volwassenheid en vele functies gebruiken we RabbitMQ bij onze projecten en ook in deze blog. In deze blog gebruik ik vooral de basisfuncties die RabbitMQ biedt. De geavanceerdere functies worden in een toekomstige blog toegelicht.
Bij het gebruik van RabbitMQ zijn enkele begrippen van belang:
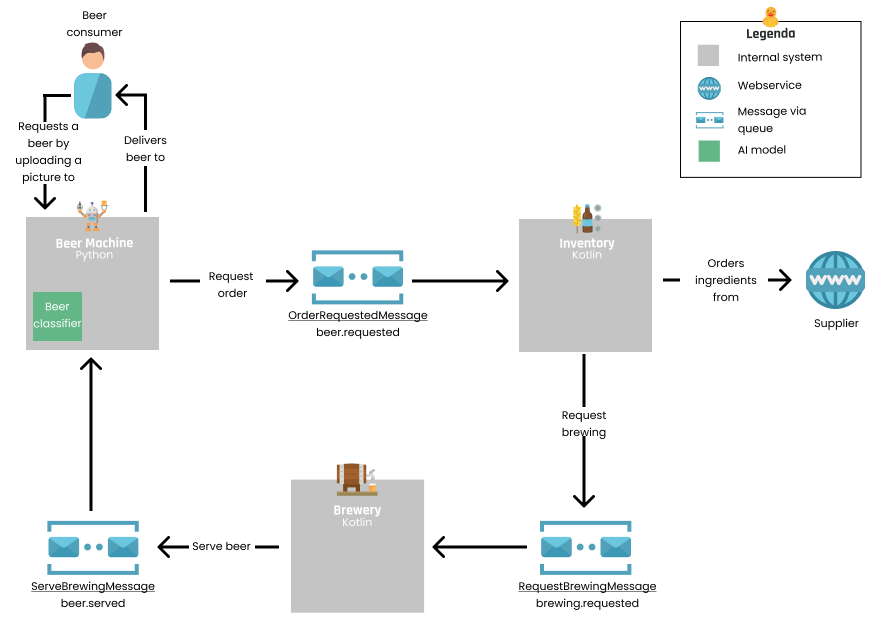
In onderstaande figuur is een voorbeeld te zien van hoe twee services communiceren via RabbitMQ. De Inventory service stuurt een bericht naar de routing key "brewing.requested". Die service hoeft niet te weten wat er daarna mee gebeurt, omdat RabbitMQ de aflevering van het bericht verzorgt. De brewery service registreert een queue waarop de berichten van die routing key geplaatst zullen worden. Hierdoor ontvangt de brewery die berichten van de inventory service.
.png?width=1274&name=Blogvisual-2%20(1).png)
Om deze berichten via RabbitMQ te kunnen versturen en ontvangen is één stuk configuratie nodig: een gebruiker die daarvoor de rechten heeft. Deze configuratie ziet er als volgt uit en geeft de gebruiker (beer) volledige rechten. Het is mogelijk en zelfs aan te raden om meerdere gebruikers aan te maken met precies de juiste rechten voor de service die het account gebruikt.
{
|
Wat van belang is in de configuratie is het wachtwoord. Dit is namelijk het woord "brewing", gehasht op de manier die wordt beschreven door de documentatie van RabbitMQ. Dit wachtwoord kan gebruikt worden door de services die verbinden met RabbitMQ.
Voor de configuratie van RabbitMQ in Kotlin wordt gebruikgemaakt van Spring. In Spring worden de exchange, queue en binding gedefinieerd door het registreren van beans. Dit zorgt ervoor dat de queue beschikbaar is om op te luisteren.
Voor het verzenden van berichten wordt gebruik gemaakt van het RabbitTemplate van Spring. Deze berichten worden verstuurd als JSON, waarvoor een object mapper die geschikt is voor Kotlin data classes mee wordt gegeven. Met die object mapper worden alle soorten berichten op de juiste manier ge(de)serialiseerd van en naar JSON. Het RabbitTemplate wordt gebruikt om berichten te versturen, waarvan de MessageSender gebruik maakt. De MessageSender wordt bij het brouwproces in deze blog besproken.
@Configuration |
Met bovenstaande code hebben we de benodigde beans beschikbaar gesteld. Hoe weet Spring nu met welke RabbitMQ hij moet verbinden? Dat wordt door Spring Boot uit meerdere configuratiebronnen gelezen, bijvoorbeeld uit environment variabelen en een application.yaml:
spring: |
In Python kan geen gebruik gemaakt worden van beans die de juiste gegevens automatisch registreren bij RabbitMQ. In plaats daarvan maken we gebruik van Pika, een library voor het gebruik van RabbitMQ in Python. De gegevens die nodig zijn voor het aanmaken van de exchange, queue en binding zijn gelijk aan de gegevens die gebruikt worden in Kotlin.
Configuratie van RabbitMQ in Python met Pika
PERSISTENT_MODE: int = 2 |
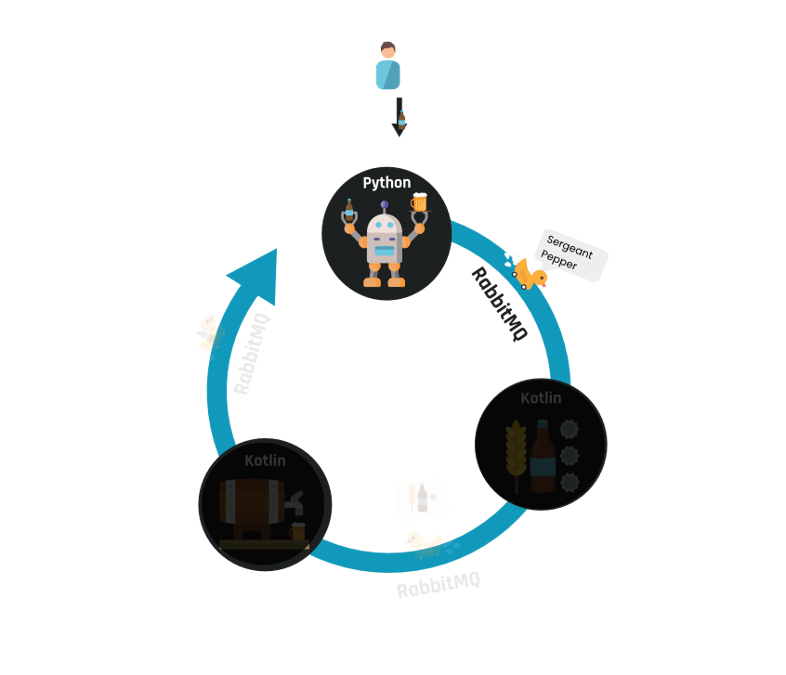
Het bierbrouwproces begint in Python, waar de gebruiker vanuit de interface een foto uploadt. Op de foto is een bierflesje te zien van een type die door het model herkend kan worden, de Sergeant Pepper. In onze vorige blog, over de AI Training Engine, hebben we laten zien hoe we dit model hebben getraind.
Omdat het voor de rest van het proces van belang is welk bier gebrouwen moet worden, wordt eerst bepaald welk bier op de foto te zien is. Dit gebeurt door middel van een image classification model, dé reden waarom we Python willen gebruiken. Het model geeft de waarschijnlijkheid aan van de bieren waarmee het model getraind is, waarna het bier met de hoogste score gebruikt wordt.
Nu het soort bier bekend is wordt een opdracht tot het inkopen van ingrediënten verstuurd naar de inventory service. Hiervoor wordt een message sender gebruikt:
def send_message(exchange_name: str, routing_key: str, message: BaseMessage): connection: BlockingConnection = rabbit_connector.get_connection() channel: BlockingChannel = connection.channel() channel.confirm_delivery() rabbit_connector.exchange_declare( channel=channel, exchange_name=exchange_name, exchange_type="direct" ) try: rabbit_connector.basic_publish( channel=channel, exchange_name=exchange_name, routing_key=routing_key, message=message ) connection.close() except pika.exceptions.UnroutableError as e: print("Failed to send message: ", e) connection.close() |
In deze message sender wordt een verbinding naar RabbitMQ opgestart, waarna het bericht op de meegegeven exchange en routing key wordt gepubliceerd.
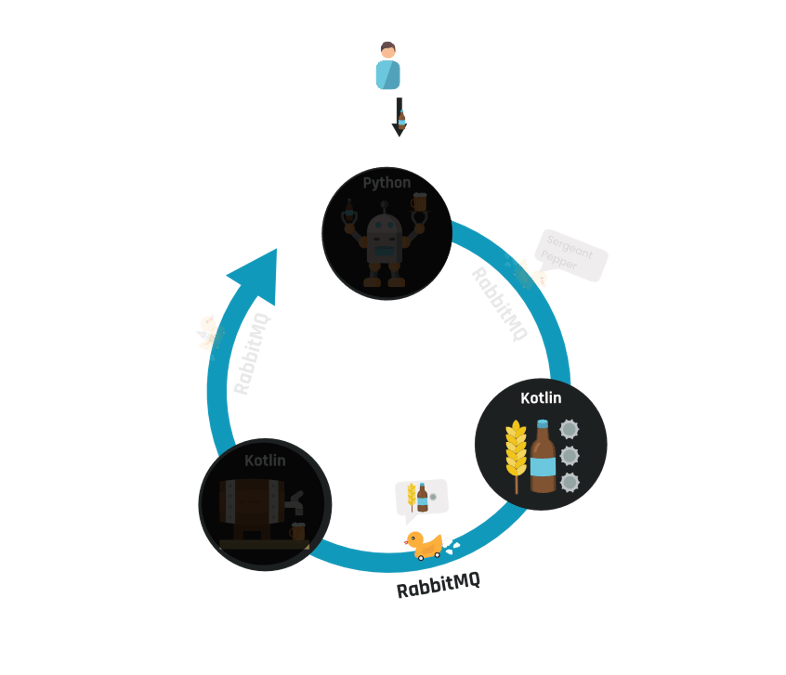
Het verstuurde bericht wordt in Kotlin ontvangen, in de inventory service. Dit komt doordat deze service de routing key gebonden heeft aan een queue en naar berichten op deze queue luistert. Deze service gaat op basis van het ontvangen soort bier de juiste ingrediënten bestellen.
Het ontvangen van het bericht gebeurt via een message receiver:
Message receiver in Kotlin
@Component |
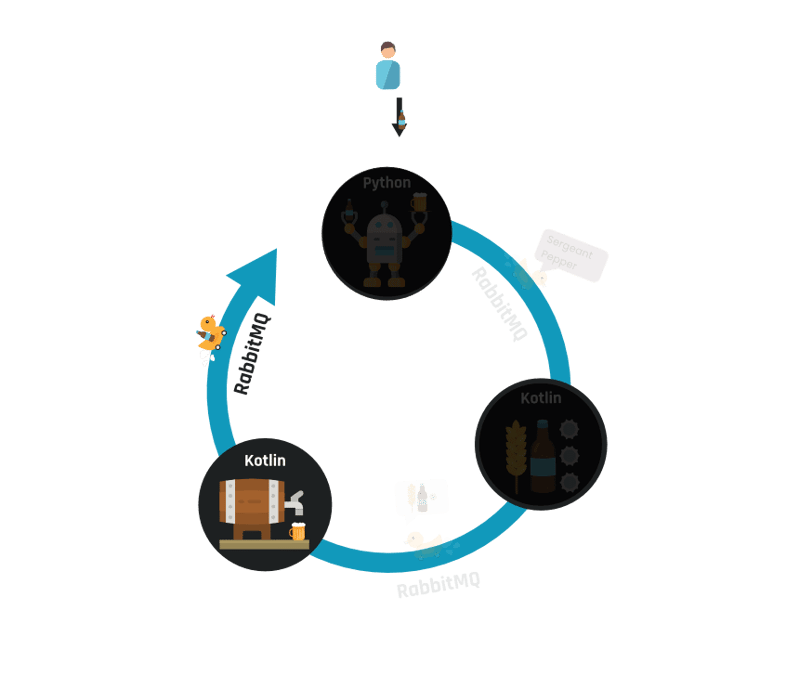
Na het ontvangen van het bericht in Kotlin wordt het brouwen gestart. De benodigde ingrediënten zijn ondertussen in de inventory service besteld, waarna de opdracht tot brouwen naar de brewery service is gestuurd. Als het brouwen klaar is wordt een bericht van de brewery teruggestuurd naar Python. Het verzenden van dit bericht gebeurt via een message sender in Kotlin:
class MessageSender( |
Zoals bij Python wordt het bericht hier ook naar een routing key gestuurd. Wel is hierbij de verbinding naar RabbitMQ al door Spring opgezet en wordt de exchange gebruikt die in de configuratie van Spring is gedefinieerd.
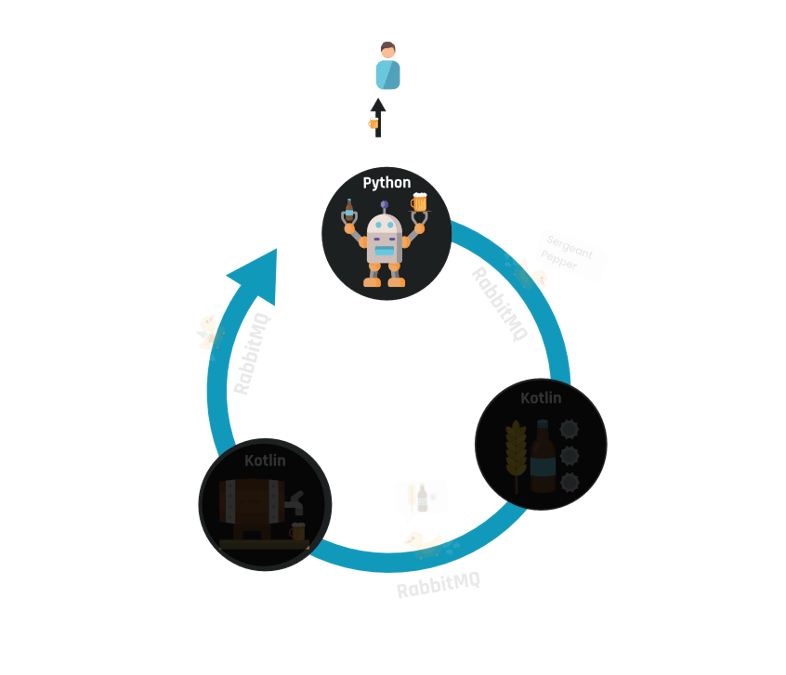 Tot slot ontvangt de Python service, waar het hele proces is gestart, de resultaten van het brouwproces. Zodra deze het bericht ontvangt, wordt het biertje aan de gebruiker geserveerd en kan hij genieten van een lekkere Sergeant Pepper!
Tot slot ontvangt de Python service, waar het hele proces is gestart, de resultaten van het brouwproces. Zodra deze het bericht ontvangt, wordt het biertje aan de gebruiker geserveerd en kan hij genieten van een lekkere Sergeant Pepper!
Het bericht waar de resultaten in staan, verzonden door de brewery service, wordt ontvangen in een message receiver:
def start_receiving(exchange_name: str, queue_name: str, routing_key: str, callback: Callable[[BlockingChannel, spec.Basic.Deliver, spec.BasicProperties, bytes], None]): |
Message receiver callback in Python
def __received_served_brewing_callback(channel: BlockingChannel, method: spec.Basic.Deliver, properties: spec.BasicProperties, body: bytes): |
De bovenste functie biedt een generieke manier voor het ontvangen van berichten. Vervolgens wordt deze gebruikt met de tweede functie als callback, die het bericht uitleest en verwerkt.
De broncode van de applicatie is beschikbaar via GitHub. Hierin staat de code voor alle delen van de applicatie, samen met een docker-compose configuratie waarmee RabbitMQ en de Kotlin-delen van de applicatie worden opgestart. Voor RabbitMQ wordt de standaardconfiguratie gebruikt in combinatie met de configuratie van de gebruiker met de juiste rechten. Verder is het wait-for-it.sh script belangrijk, die ervoor zorgt dat gewacht wordt met het starten van de Kotlin-services, totdat RabbitMQ is opgestart. De Python applicatie (in het mapje gui) moet los gestart worden.
Verdere instructies voor het bouwen en starten van de applicatie zijn te vinden in de README
In deze blog heb ik je meegenomen in het maken van een applicatie die communiceert via RabbitMQ. Door de services te ontkoppelen van elkaar, ontstaat er flexibiliteit in wat de services doen en welke technologie er gebruikt wordt. Als casus heb ik de combinatie Kotlin voor de domeinlogica en Python voor AI laten zien.
Deze opzet maakt gebruik van de basisfuncties van RabbitMQ. In een toekomstige blog nemen we je verder mee in de geavanceerde mogelijkheden voor traceability, foutafhandeling en deployment!
| TechLab
Door Marcel van Heerdt / okt 2024