Vergemakkelijk het trainen van AI-modellen met de AI Training Engine
Door Erik Evers / jun 2021 / 1 Min

Door Erik Evers / / 9 min

Wat ons betreft is parallel werken in Python een ongewenste uitdaging! Waar we gewend zijn dat in talen als Kotlin het paralleliseren erg gemakkelijk toe te passen is door gebruik te maken van coroutines, hebben we binnen Python meerdere pogingen gedaan welke steevast uitliepen op een fiasco. Binnen ons team werken we veel met AI-gerelateerde toepassingen, waarbij je er momenteel nog niet aan ontkomt om Python te gebruiken.
Tijdens het verrichten van onderzoek kwamen we Dask op het spoor. Dask beschrijft zichzelf als een flexibele library voor het paralleliseren en optimaliseren van berekeningen. Het bevat vele mogelijkheden die het verwerken van data in Python een stuk gemakkelijker maken.
Deze blog gaat in op de basisonderdelen van Dask en geeft een voorbeeld van hoe er tijdswinst te behalen is bij het verwerken van en uitvoeren van berekeningen op meerdere CSV-bestanden. In de blog worden voorbeelden aangehaald. Deze zijn terug te vinden in de volgende repository: https://github.com/AvisiLabs/atl-dask
Dask maakt het erg gemakkelijk om eigen algoritmes te paralleliseren. Door delayed toe te passen op een functie wordt deze lazy. Dit houdt in dat de functie niet uitgevoerd wordt, maar onderdeel wordt van een task graph. De structuur van deze task graph bepaalt in welke volgorde acties uitgevoerd worden. En nog belangrijker, welke acties parallel aan elkaar uitgevoerd kunnen worden.
Om de werking hiervan uit te leggen, kijken we naar een voorbeeld. In het onderstaande codeblok zien we twee functies:
drink_round_of_beer en get_total_numbers_of_beer_drunk. De eerste functie bepaalt een willekeurig nummer en geeft deze terug. Dit is het aantal gedronken bieren. De tweede functie telt het aantal gedronken bieren van twee rondes bij elkaar op. In de functies roepen we de functie sleep aan. Dit doen we zodat later duidelijk te zien is welke tijdswinst te behalen is bij het toepassen van delayed.
import random
from time import sleep
def drink_round_of_beer() -> int:
print("Start drinking beer")
sleep(10)
number_of_drinks = random.randint(2, 10)
print("Drank {} beers".format(number_of_drinks))
return number_of_drinks
def get_total_numbers_of_beer_drunk(first_round: int, second_round: int) -> int:
sleep(10)
return first_round + second_round
In het codeblok hierboven roepen we de functies sequentieel aan. We drinken twee rondes bier en tellen het aantal gedronken bieren bij elkaar op. Zo worden er bijvoorbeeld in de eerste ronde vijf bieren gedronken en in de tweede ronde acht bieren. Er is 30 seconden nodig om deze code uit te voeren; twee keer tien seconden voor het drinken van een ronde aan bier en één keer tien seconden voor het optellen van het aantal gedronken bieren in de rondes. Waar get_total_numbers_of_beer_drunk afhankelijk is van de uitkomsten van het tweemaal aanroepen van de functie drink_round_of_beer, is het tweemaal uitvoeren van drink_round_of_beer niet afhankelijk van elkaar. Dit kunnen we parallel aan elkaar uitvoeren. Om dit te doen wrappen we de functies in het bestaande algoritme met de delayed functie van Dask, zoals te zien is in onderstaand codeblok.
from dask import delayed
first_person_round = delayed(drink_round_of_beer)()
second_person_round = delayed(drink_round_of_beer)()
total = delayed(get_total_numbers_of_beer_drunk)(first_person_round, second_person_round)
print(total)
Wanneer we deze code uitvoeren, wordt er niet een getal geprint, maar wordt na enkele milliseconden het volgende geprint wordt: Delayed('get_total_numbers_of_beer_drunk-0a1645e1-62ce-4cae-a9c8-1f94ae81673f'). We krijgen een Delayed-object terug in plaats van de daadwerkelijke uitkomst. Dit Delayed-object bevat een task graph, waarin opgenomen is hoe de functies uitgevoerd moeten worden. Deze task graph kunnen we inzien door op het Delayed-object de methode visualize aan te roepen. Hierdoor krijgen we de volgende task graph te zien:
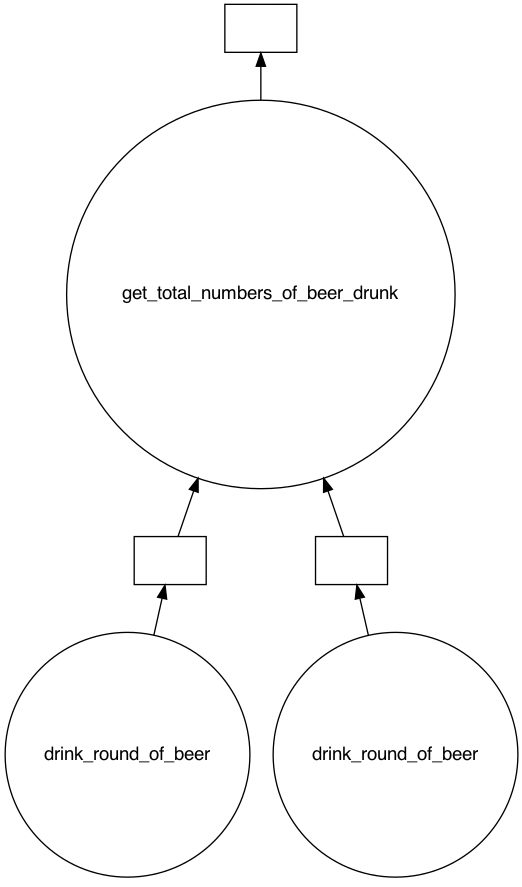
Zoals verwacht worden de twee aanroepen naar de functie drink_round_of_beer parallel aan elkaar uitgevoerd. Vervolgens worden de uitkomsten hiervan gebruikt om mee te geven aan de functie get_total_numbers_of_beer_drunk. Om de task graph uit te voeren, roepen we op het Delayed-object de compute-methode aan. De uitvoer hiervan duurt twintig seconden, terwijl het uitvoeren van de code zonder delayed 30 seconden duurde. We hebben een tijdswinst van tien seconden geboekt, doordat de twee aanroepen naar drink_round_of_beer parallel hebben uitgevoerd.
Een alternatief op het wrappen van functie-aanroepen met de delayed-methode is het plaatsen van een delayed-annotatie op de declaratie van de functies zoals in onderstaand voorbeeld. Hierdoor wordt elke aanroep naar één van de twee functies lazy. In dit geval kan je de functies aanroepen net zoals je normaliter zou doen in Python. In dit geval dus gelijk aan het eerste voorbeeld wat gegeven werd voordat delayed toegepast werd.
import random
from dask import delayed
from time import sleep
@delayed
def annotated_drink_round_of_beer() -> int:
print("Start drinking beer")
sleep(10)
number_of_drinks = random.randint(2, 10)
print("Drank {} beers".format(number_of_drinks))
return number_of_drinks
@delayed
def annotated_get_total_numbers_of_beer_drunk(first_round: int, second_round: int) -> int:
sleep(10)
return first_round + second_round
Het is niet altijd gewenst om in eigen algoritmes alle aanroepen lazy te maken. Soms bevat je algoritme logica die bepaalt welke functionaliteit binnen het algoritme uitgevoerd moet worden. Deze logica wil je direct evalueren. Om dit te illusteren kijken we naar het volgende voorbeeld. Hierin zijn de methoden drink_one_beer en drink_two_beers opgenomen die het aantal gedronken bieren teruggeven. Daarnaast hebben we de methode get_total_number_of_beers die een lijst van aantallen van gedronken bieren bij elkaar optelt
from dask import delayed
from time import sleep
from enum import IntEnum
def drink_one_beer() -> int:
sleep(10)
return 1
def drink_two_beers() -> int:
sleep(10)
return 2
def get_total_number_of_beers(numbers_of_beers):
sleep(10)
return sum(numbers_of_beers)
Weekdays = IntEnum('Weekdays', 'SUN MON TUE WED THU FRI SAT', start=0)
We lopen door alle dagen van de week heen. Op doordeweekse dagen willen we graag één bier drinken en op vrijdag en in de weekenden twee bieren.
results = []
for day in Weekdays:
if (day in (Weekdays.FRI, Weekdays.SAT, Weekdays.SUN)):
result = drink_two_beers()
else:
result = drink_one_beer()
results.append(result)
total = get_total_number_of_beers(results)
print(total)
Dask toe te passen, duurt dit één minuut en twintig seconden. Hier lijkt een flinke snelheidswinst te behalen te zijn. De aanroepen naar drink_one_beer en drink_two_beers kunnen prima parallel uitgevoerd worden. Daarom wrappen we de aanroepen naar deze twee functies met de delayed-methode.
results = []
for day in Weekdays:
if (day in (Weekdays.FRI, Weekdays.SAT, Weekdays.SUN)):
result = delayed(drink_two_beers)()
else:
result = delayed(drink_one_beer)()
results.append(result)
total = delayed(get_total_number_of_beers)(results)
print(total)
Als we vervolgens kijken naar de task graph die dit oplevert, zien we dat de logica rondom de weekdagen al verwerkt is. Voor sommige dagen wordt drink_one_beer en voor andere dagen drink_two_beers aangeroepen. Er is een combinatie gemaakt tussen de lazy (aanroepen van de functies) en niet-lazy (uitvoeren van het if-statement) onderdelen van ons algoritme. Waar de uitvoer eerst één minuut en twintig seconden duurde, duurt de uitvoer met deze opzet slechts twintig seconden!
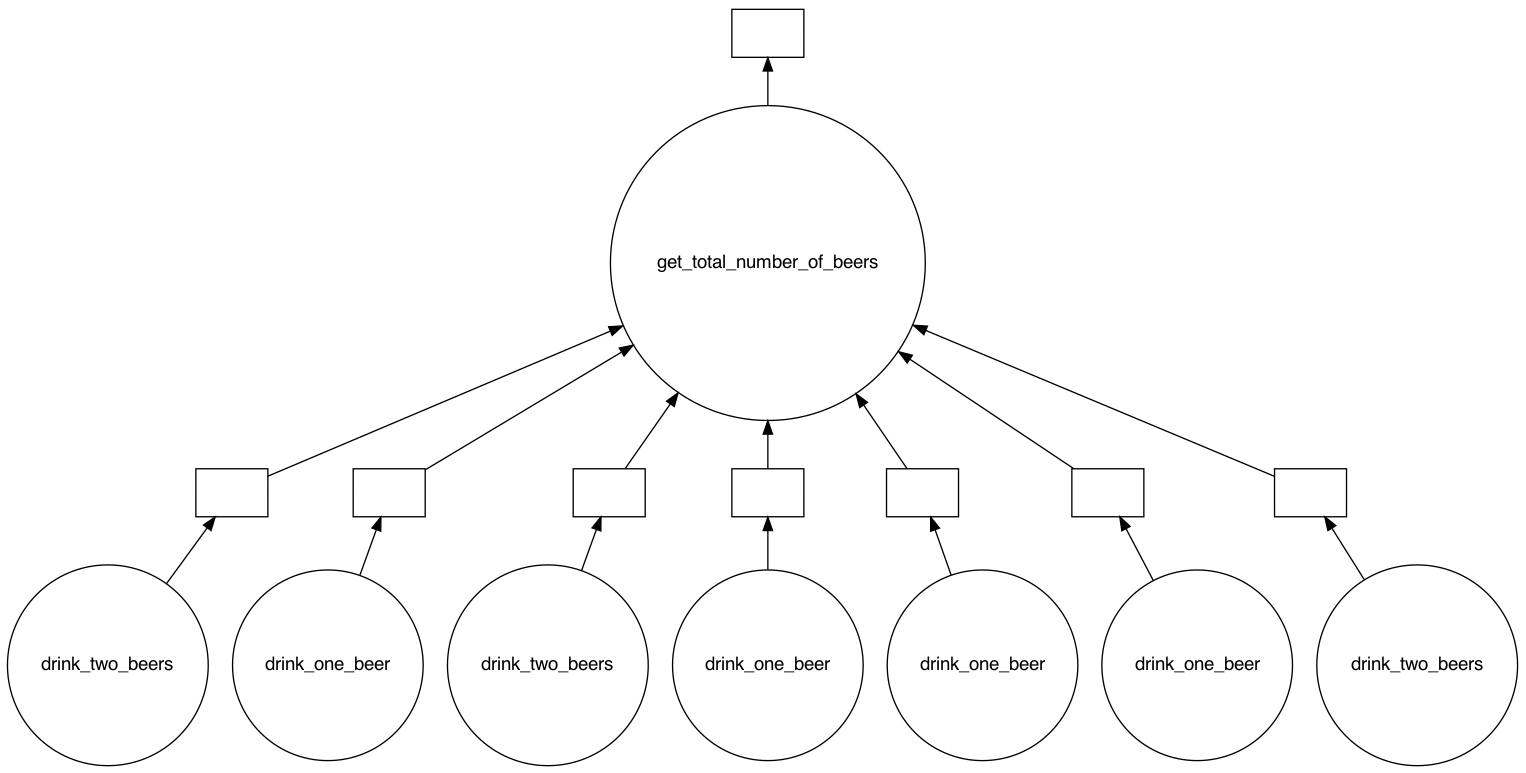
Tot nu toe hebben we gekeken naar voorbeelden waarbij Dask toegepast wordt binnen eigen algoritmes. Nog vaker maken we in Python gebruik van verschillende grotere libraries, zoals NumPy en Pandas. Dit veelal met het doel om grotere hoeveelheden data te verwerken en hierop berekeningen uit te voeren. Hierbij kunnen uitdagingen naar voren komen die we aan kunnen pakken door high-level collections van Dask toe te passen. Denk hierbij aan: de doorlooptijd, de hoeveelheid te verwerken data en data die verspreid is over meerdere bestanden.
Dask biedt ondersteuning voor verschillende high-level collections: bags, arrays en dataframes. Deze collections bieden gelijke opties aan als bekende libraries in Python en zijn daarom eenvoudig toe te passen binnen zowel bestaande als nieuwe projecten. De collections berusten allen op het feit dat de data onderwater opgesplitst wordt, waardoor het mogelijk wordt om deze parallel op meerdere machines of cores te verwerken. Zo wordt het ook mogelijk om larger-than-memory data (data die meer ruimte inneemt dan het totaal beschikbare RAM-geheugen) te verwerken. Waar de data onderwater opgesplitst is, merk je daar als gebruiker weinig van. Je behandelt de opgesplitste data, bijvoorbeeld meerdere NumPy arrays waaruit een Dask array bestaat, als één array.
Hieronder volgt een overzicht van de verschillende collections met hun belangrijkste eigenschappen.
| Collection | Implementeert | Splitst op in | Gebruikt voor |
| Array | Een subset van de NumPy ndarray interface | Meerdere Numpy arrays | Verwerking van larger-than-memory arrays |
| Bag | Functies die bekend zijn op normale Python-objecten zoals map, filter, fold en groupby | Meerdere partities | Semi-gestructureerde data aan het begin van een dataverwerkingproces |
| Dataframe | Een subset van de Pandas dataframe interface | Meerdere Pandas dataframes | Situaties waarbij Pandas gebruikt wordt en problemen optreden door de grootte of de verwerkingssnelheid |
Het is goed om te melden dat de collections niet in alle gevallen een complete vervanging kunnen zijn van het gebruik van de originele libraries. Zoals hierboven aangegeven wordt, implementeren array en dataframe een subset van de interfaces van de originele libraries. Dit betekent dat veelgebruikte methoden ondersteunt zullen worden, maar dat dit niet het geval is voor erg specifieke methoden.
Om goed in te zien welke winst te behalen is bij het toepassen van een Dask high-level collection, gaan we in op een voorbeeld waarbij eerst een oplossing geprogrammeerd wordt zonder Dask te gebruiken. Vervolgens kijken we naar hoe een oplossing aangepast wordt, zodat deze Dask gebruikt en welke voordelen dat biedt.
We gaan door met onze favoriete hobby bij Labs; bier drinken. We hebben een dataset tot onze beschikking met daarin veel verschillende soorten bieren. Daarnaast hebben we data beschikbaar over ratings die gegeven zijn door andere bierdrinkers. We zijn erg benieuwd wat de gemiddelde rating is die gegeven is aan bieren die vallen onder dezelfde stijl. Bijvoorbeeld de gemiddelde rating voor alle bieren met als stijl 'American IPA'.
De dataset die we tot onze beschikking hebben bestaat uit CSV-bestanden. Om inzicht te krijgen in de inhoud hiervan volgt hieronder een voorbeeld van de inhoud van de CSV-bestanden. Als eerste behandelen we een voorbeeld van het CSV-bestand met alle bieren en daarna van een van de CSV-bestanden met ratings.
| id | name | brewery_id | state | country | style | availability | abv | notes | |
| 202522 | Olde Cogitator | 2199 | CA | US | English Oatmeal Stout | Rotating | 7.3 | No notes at this time. | f |
| id | beer_id | username | date | text | look | smell |
| 5737966 | 57164 | grittybrews | 2011-09-19 | Poured cola brown with a finger of dark khaki head. Mildly sweet aroma of milk chocolate and hints of coffee. Somewhat low carbonation and a creamy, light mouthfeel. Cocoa and caramel sweetness up front and a roasty, lingering coffee bitterness on the finish. A little on the thin side but very pleasant tasting and easy-drinking. Comes across lighter than the ABV would indicate. | 4.0 | 4.5 |
| feel | overall | score | taste |
| 3.5 | 4.0 | 4.07 | 4.0 |
Er is een nadeel: de gegeven ratings zijn verdeeld in CSV-bestanden met 1.000.000 rijen per bestand. Dit betekent dat we deze apart van elkaar moeten gaan inlezen. Om te komen tot de gemiddelde rating voor alle bieren onder een bepaalde stijl, voeren we de volgende stappen uit:
Van deze stappen zijn de eerste twee stappen gelijk bij zowel het wel als niet toepassen van Dask. Bij de derde stap gaan we daadwerkelijke verschillen zien.
In de eerste stap lezen we alle bieren in door gebruik te maken van de library Pandas. Deze biedt de functie read_csv, waarmee we gemakkelijk de bieren kunnen inlezen naar een dataframe.
import os
import pandas as pd
df_beers = pd.read_csv("beers.csv")
Nadat we de bieren hebben ingeladen, kunnen we een lijst maken van alle beer id's die vallen onder de gekozen bierstijl.
style_to_search = "American IPA"
beer_ids = df_beers[df_beers["style"]==style_to_search]["id"].unique()
Nu we alle beer id's hebben van de bieren die vallen onder onze gekozen bierstijl, kunnen we de reviews hierop filteren en de gemiddelde score bepalen. Op dit onderdeel gaan we daadwerkelijk de winst zien die wij boeken door Dask te gebruiken.
Als eerste werken we de oplossing uit, waar we niet gebruik maken van Dask. Dit doen we door de volgende stappen uit te voeren:
import glob
csv_files = glob.glob(os.path.join("data", "reviews-*.csv"))
means = []
for csv_file in csv_files:
df = pd.read_csv(csv_file)
mean = df[df["beer_id"].isin(beer_ids)]["overall"].mean()
means.append(mean)
print("Average rating:", sum(means) / len(means))
Het uitvoeren van deze logica neemt, uitgezonderd het bepalen van de paden naar de CSV-bestanden, ongeveer 50 seconden in beslag. Als tweede werken we de oplossing uit, waarbij we wel gebruik maken van Dask. Dit doen we door de volgende stappen uit te voeren:
import dask.dataframe as dd
from dask.distributed import Client
client = Client()
filename = os.path.join("data", "reviews-*.csv")
df = dd.read_csv(filename)
average = df[df["beer_id"].isin(beer_ids)]["overall"].mean()
print("Average rating:", average.compute())
client.close()
Het uitvoeren van deze logica neemt ongeveer 10 seconden in beslag. Hiermee behalen we dus een flinke winst! De vraag is nu: waarom hebben we die winst?
In het voorbeeld zonder Dask hebben we te maken met meerdere CSV-bestanden, welke we ook als zodanig moeten behandelen. We loopen sequentieel door alle bestanden heen. In het voorbeeld met Dask behandelen we de verschillende CSV-bestanden als één bestand. We geven namelijk een pad met een wildcard daarin mee aan de read_csv-functie, waardoor we uiteindelijk één Dask dataframe hebben die over meerdere CSV-bestanden gaat. Wanneer we vervolgens acties uitvoeren op dit dataframe, bouwen we stiekem ook een task graph op. Als we deze task graph inzien, zien we dat veel acties parallel aan elkaar uitgevoerd worden, om zodoende het gemiddelde te bepalen over alle CSV-bestanden.

Dat we daadwerkelijk met meerdere CSV-bestanden werken die parallel verwerkt worden, zien we het beste terug rechtsonderin de task graph.
Een deel hiervan is hieronder te zien in de afbeelding. Hier zien we dat read-csv verschillende keren parallel aan elkaar wordt aangeroepen.
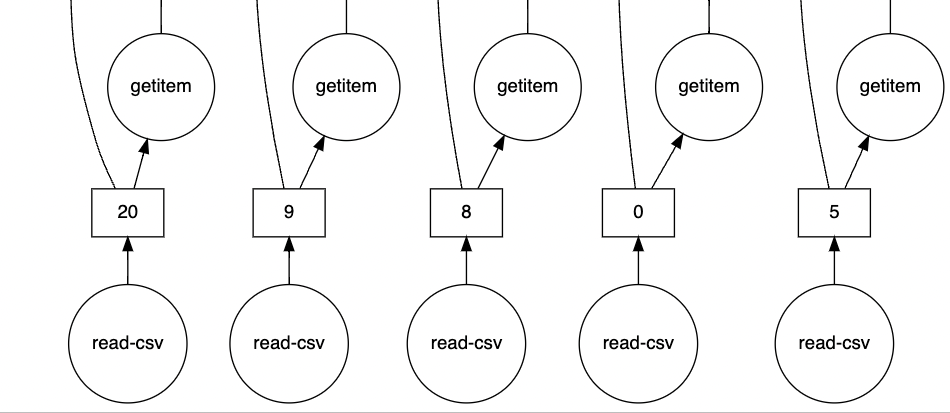
Bij het uitgewerkte voorbeeld werd al kort ingegaan op het feit dat een client gestart wordt, waar vervolgens de berekeningen op uitgevoerd worden. Wat nog rest is de vraag hoe de berekeningen uit de opgestelde task graph daadwerkelijk uitgevoerd worden. Dask heeft vier schedulers die beschikbaar worden gesteld.
|
Naam
|
Omschrijving
|
|---|---|
| Threaded | Een scheduler die ondersteunt wordt door een thread pool |
| Processes | Een scheduler die ondersteunt wordt door een process pool |
| Single-threaded | Een synchrone scheduler, die goed bruikbaar is voor debugging |
| Distributed | Een gedistribueerde scheduler voor het uitvoeren van graphs over meerdere machines |
De eerdergenoemde high-level collections hebben een default scheduler die gebruikt wordt. Deze is gebaseerd op welke het beste toepasbaar is bij de acties die uitgevoerd kunnen worden op de collections. Zo maken de array en dataframe standaard gebruik van de threaded scheduler. Om meer inzicht te krijgen in hoe Dask op de achtergrond werkt, is het aan te bevelen om binnen JupyterLab gebruik te maken van de dask-labextension. Hierdoor kan een dashboard geopend worden, waar onder andere inzicht gegeven wordt in hoe de taken uit de task graph uitgevoerd worden. Een voorbeeld hiervan is te zien in onderstaande afbeelding.
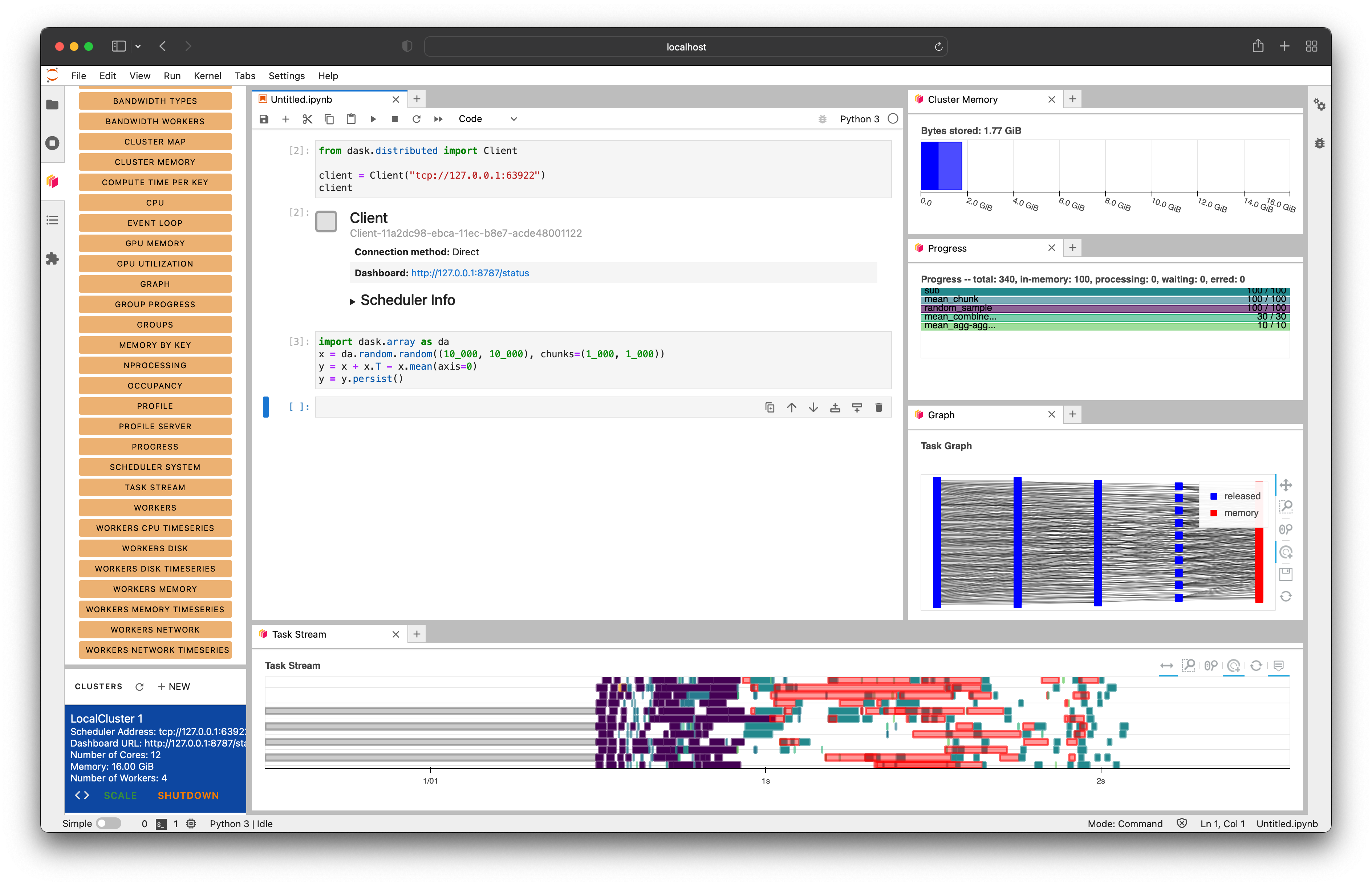
De beste manier om Dask beter te begrijpen is door er zelf mee aan de slag te gaan. In de volgende repository: ATL Dask, zijn verschillende notebooks opgenomen die de voorbeelden bevatten die in deze blog behandeld zijn. Ga er zelf mee aan de slag en probeer daarbij ook het eerdergenoemde dashboard uit. Verder is het aan te bevelen om naar de officiële website van Dask te gaan. Hier is veel meer documentatie te vinden. Zowel documentatie over de onderdelen die behandeld zijn in deze blog als documentatie over nog meer toepassingen van Dask. Denk bijvoorbeeld aan Dask ML die het mogelijk maakt om machine learning in Python op te schalen!
| TechLab
Door Erik Evers / okt 2024